Deep Q-Learning
2018-07-12
Reinforcement learning tries to emulate the process by which humans and animals are thought to learn. The motivation behind attempting to reproduce the learning process of animals or humans is to create a very general algorithm that could allow an agent to function in a wide variety of settings, with no previous knowledge of the environment.
In general reinforcement learning algorithms follow a procedure of an agent taking an action within its environment, receiving some reward as a result of that action, followed by an update to the agent's action policy, based on the rewards the agent has received.
When an agent has no apriori knowledge of the environment that it is interacting with, this is known as model free reinforcement learning. Q-learning is one such model free algorithm. The DeepMind lab achieved a breakthrough in 2013, when they combined Q-learning with convolutional neural nets, which allowed an agent to play various Atari games at a human level, and some cases beyond human level.

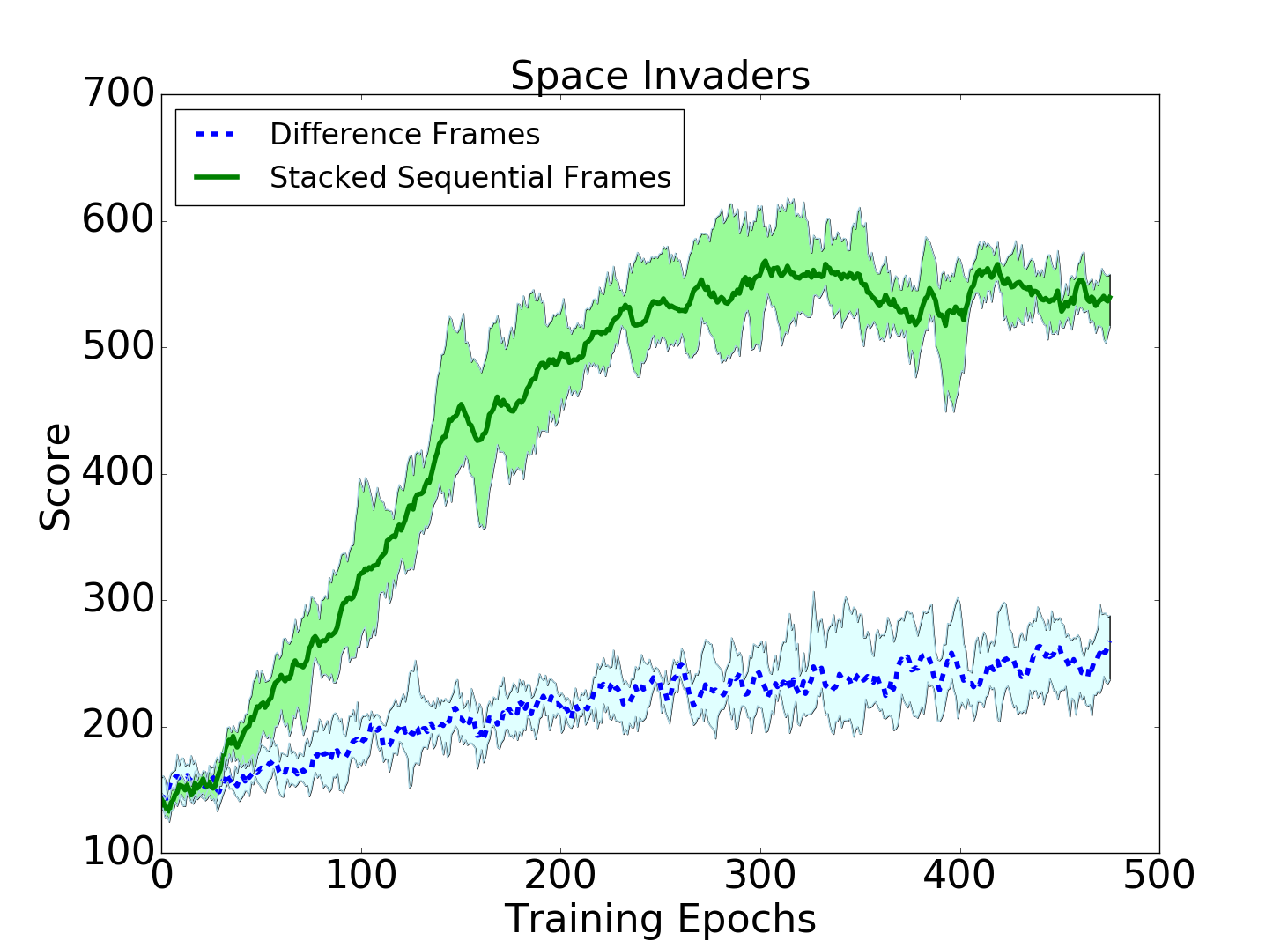
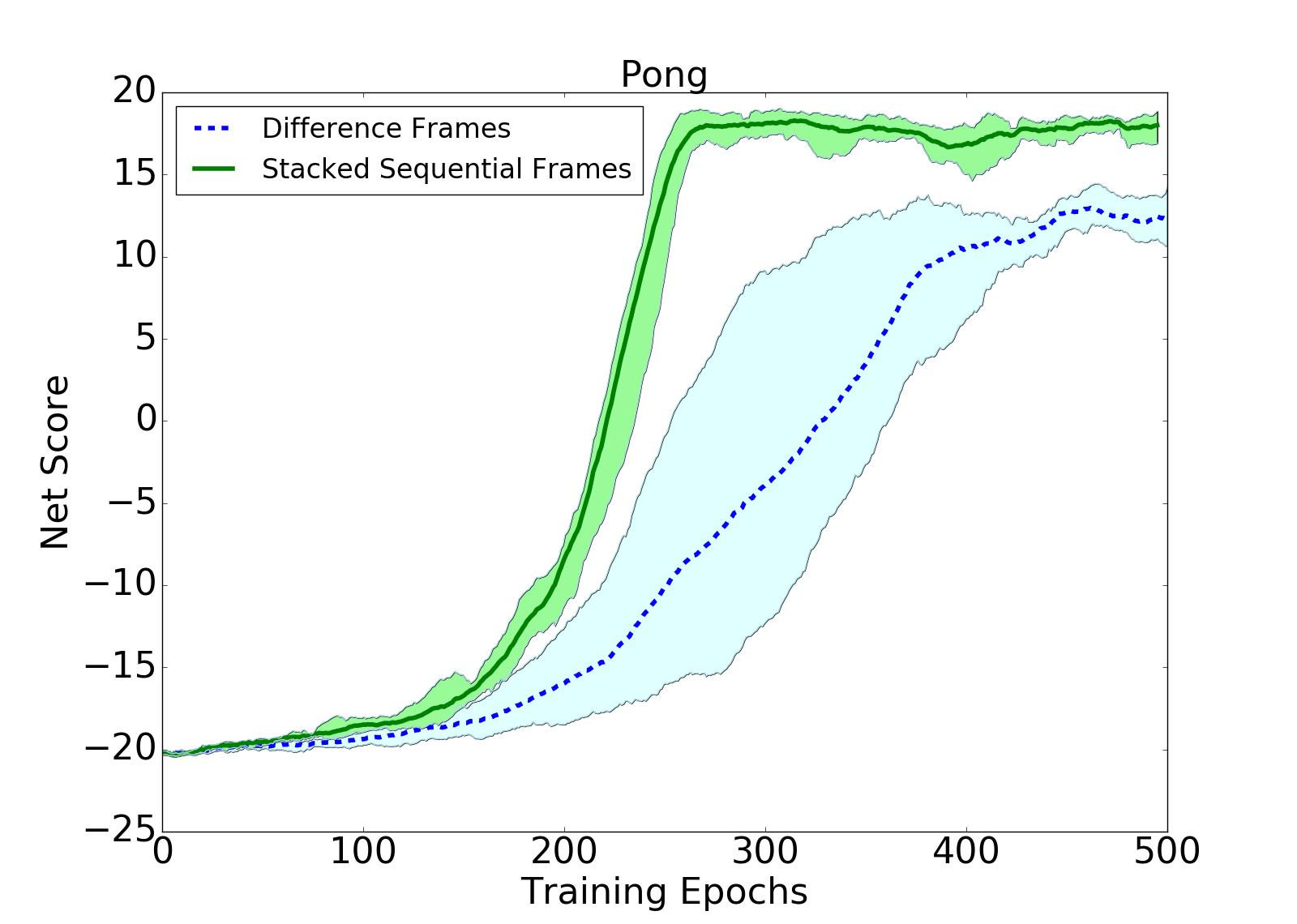
For this project I reproduced DeepMind's original research paper, and conducted my own experiments regarding the influence of how environment state information is presented to the agent. Traditionally, when applying Q-learning to Atari games, the current state of the environment is represented by stacking four sequential game frames. Stacking frames allows essential state information like velocity to be inferred.
As an alternative I conducted experiments using difference frames to represent environment state, instead of stacked sequential frames. A difference frame is created simply by performing element-wise subtraction of two sequential emulator game frames (a frame is a 2D array of pixel values).
My experiements showed that difference frames performed similarly to stacked sequential frames on Pong, but significantly worse on Space Invaders. Likely, this is due to the increased environment complexity of Space Invaders. However, although agent performance with difference frames was diminished, the training time for the agent was reduced rather significantly due to the decreased neural network size required to process the difference frames, on the order of a few hours difference.
The video below shows an example an agent playing space invaders after approximately 8 hours of training.
The following figures show examples of training curves for both sequential and difference frames used as state representations, on Pong and Space Invaders. For a much more detailed analysis of the experiment, read my paper here.